Role Specialisation in Capture the Flag using Reinforcement Learning
Background
This is a condensed version of my Master’s thesis, presented here in a simplified form to enhance accessibility. The complete version can be downloaded here
This study explores how heterogeneous agents develop specialised roles in a capture the flag setting. Agents are trained how to play the game using reinforcement learning with simple reward signals and self-play.
To achieve this, I created a custom environment and introduced four distinct agent types, each with different attributes. Using Proximal Policy Optimisation, the agents were trained through self-play across nine experimental scenarios.
The analysis focuses on whether these built-in differences lead to emergent specialisation. To evaluate this, I developed tailored metrics and combined quantitative results with qualitative observations to better understand agent behaviour.
This study finds that heterogeneous agents trained via reinforcement learning and self-play reliably develop scalable, specialised roles that adapt dynamically in response to opposing team strategies over the course of training.
The Split — Generation 50
Loading…
Paused
Reinforcement Learning
Reinforcement learning (RL) focuses on how agents learn to map actions to rewards through trial and error, considering both immediate and long-term outcomes.
Agents must balance trying new actions to gain new knowledge, versus leveraging what they have already know works well from prior experience.
RL problems are commonly framed in terms of an agent-environment interaction cycle, where
an agent percepts the current of state of the environment, uses this information to take some
action, which then leads to some new state of the environment and a reward signal received by
the agent.
The main goal in RL is to find the optimal policy that maximises the
expected discounted sum of rewards. In CTF, if an agent is near the opposing team’s flag (the
state), the agent should pick up the flag (the action). An example of a policy is therefore; when near the opposing team’s flag, pick up the flag.
Capture the Flag (CTF) and Agent Types
Capture the Flag (CTF) is a team-based game where two teams compete to steal the opponent’s flag and return it to their own territory while avoiding being tagged. Players can tag opponents to send them back to their base. The game ends after a time limit, with the highest-scoring team winning.
In this study, CTF is used as an example of a mixed multi-agent problem, combining cooperation (within teams) and competition (between teams). Although simplified, it provides a useful environment for studying how agents learn strategies, make decisions, and coordinate over time.
I designed four types of agents, each with different abilities based on mobility, strength, damage, and how they interact with the environment.
Scout: A balanced, general-purpose agent. Scouts have higher health than other classes, allowing them to survive more tags.
Guardian: A defensive specialist. Guardians deal high damage when near their own flag but are less effective when away from it.
Vaulter: A fast, mobile agent that can move one or two squares at a time and jump over obstacles. This ability costs health each time it’s used, making the vaulter more vulnerable. It also deals less damage than other agents.
Miner: An agent that can modify the environment. Miners can remove and place certain tiles, allowing them to create paths or obstacles.
All agents can move in four directions (or stay still), capture the flag, and tag opponents. This ensures the game can function with any mix of agent types.
State, Actions, Rewards and Transitions
This environment can be thought of as a game where multiple agents interact over a series of steps. Each game runs for 500 timesteps, and at every timestep, all agents observe the situation, take an action, and the game updates. The order in which agents take actions at each turn is randomised in order to introduce uncertainty into the environment.
State: What Each Agent “Sees”
At any moment, each agent understands the game through two types of information:
The game board (what’s visible): A grid showing where everything is - agents, obstacles, and flags. Every agent can see the full board, including teammates and opponents.
Extra information (what’s not visible on the board): How much health each agent has, who is holding a flag, which team is currently ahead, and how close the game is to ending.
Together, these give the agent a complete picture of the game at that moment.
Actions: What Agents Can Do
Every agent can move up, down, left, or right, stay still, capture the flag, and tag opponents. Some agents have extra abilities:
Guardians can deal high damage when near their own flag.
Vaulters can move further or jump over obstacles, at the cost of health points.
Miners can place or remove blocks in the environment.
Not all actions are available to all agents. To make learning faster, agents are prevented from choosing actions they can’t actually perform.
Agents choose their actions using a learning method called Proximal Policy Optimisation (PPO), which gradually improves their decisions over time based on experience.
Rewards: How Agents Learn
Agents learn by receiving rewards based on what happens in the game:
+1: for capturing the enemy flag
–0.5: if their own flag is captured
Bonus points at the end if their team wins (based on how much they won by)
0: otherwise
The reward system is intentionally simple. Instead of telling agents exactly what to do, it encourages agents to figure out good strategies on their own.
Transitions: What Happens After Each Action
After all agents take an action, the game updates to a new state. This update isn’t perfectly predictable, due to the randomised order in which agents take actions at each turn.
Training Agents to Play the Game
How the Agents Are Trained
To train the agents, I used Proximal Policy Optimisation (PPO) - a widely used reinforcement learning method known for being stable and effective across many environments. I adapted the core algorithm to support multiple agents and teams. I have made the following modifications:
Sharing Knowledge Between Agents Agents on the same team share a single model, rather than each having a completely separate one. This speeds up learning, makes better use of data, and encourages coordinated behaviour. Agents types can still behave differently because their type (e.g. scout, guardian) is part of the input.
Learning From Team Experience Instead of learning only from individual experience, agents learn from the combined experience of their whole team. All actions and outcomes from teammates are pooled together and used to update the shared model, which helps agents learn teamwork more effectively.
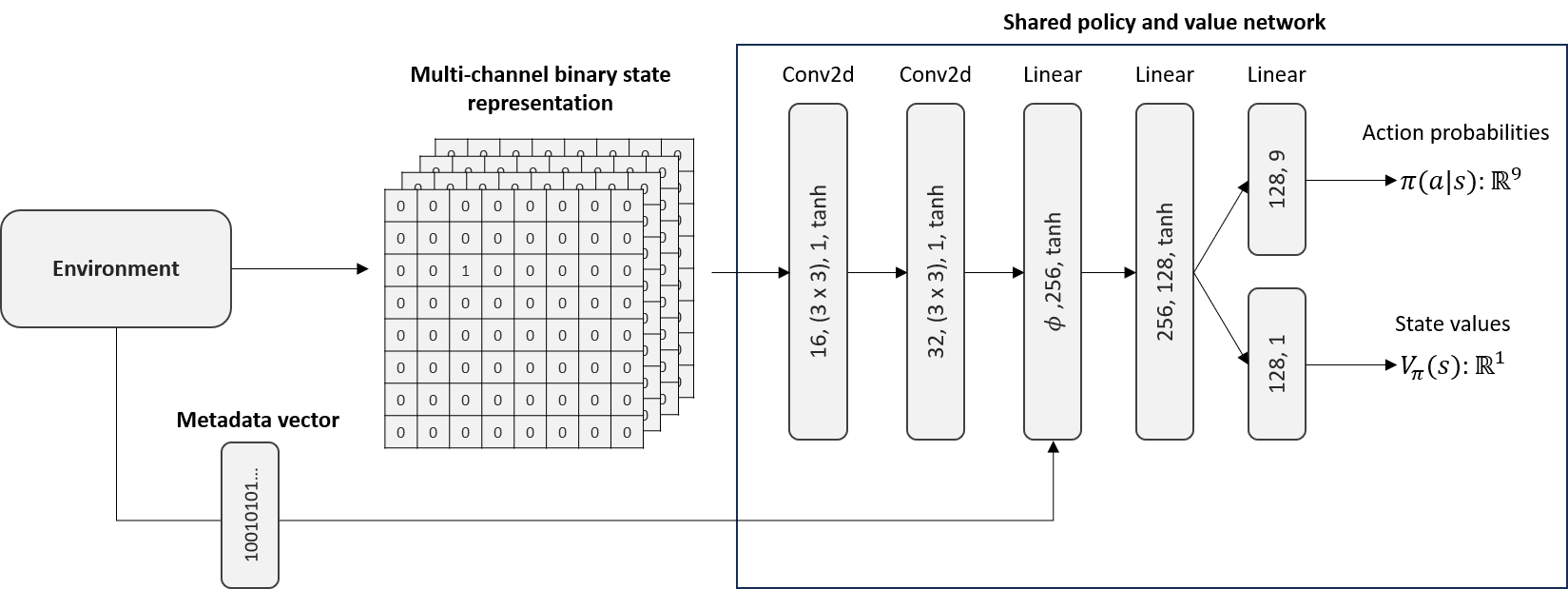
How Each Agent Makes Decisions
Each agent is powered by a neural network that decides what action to take. It takes in two types of information:
The game board — positions of agents, obstacles, and flags
Extra data — health, score, and who is holding the flag
Before processing, the game board is adjusted so that everything is viewed from the agent’s own perspective. The network produces two outputs:
An action choice — what the agent should do next
A value estimate — how favourable the current situation is
After training the network, the agent chooses its action based on the probability distribution of the action choice output.
Figure: PPO Network Architecture
Learning Through Self-Play
Agents improve by repeatedly playing against each other. Each team trains against the previous version of its opponent, creating a constantly adapting challenge.
Evaluation Metrics
To evaluate whether agents develop specialised roles, I created a set of custom metrics and used both data analysis and direct observation.
The metrics track things like flag captures, tagging, positioning on the map, teamwork, and (for miners) how they modify the environment. By comparing these behaviours across agents, it’s possible to identify roles — for example, attackers, defenders, or supportive teammates.
These metrics are collected by running multiple matches and averaging the results. Statistical tests are then used to check whether differences in behaviour are meaningful, both between individual agents and between teams.
In addition to this, I analysed how behaviours change over time, looked at movement patterns across the map, and observed actual gameplay. This helped capture more subtle strategies and provide a fuller picture of how specialisation emerges.
Experiments
Experiment 1: The Split
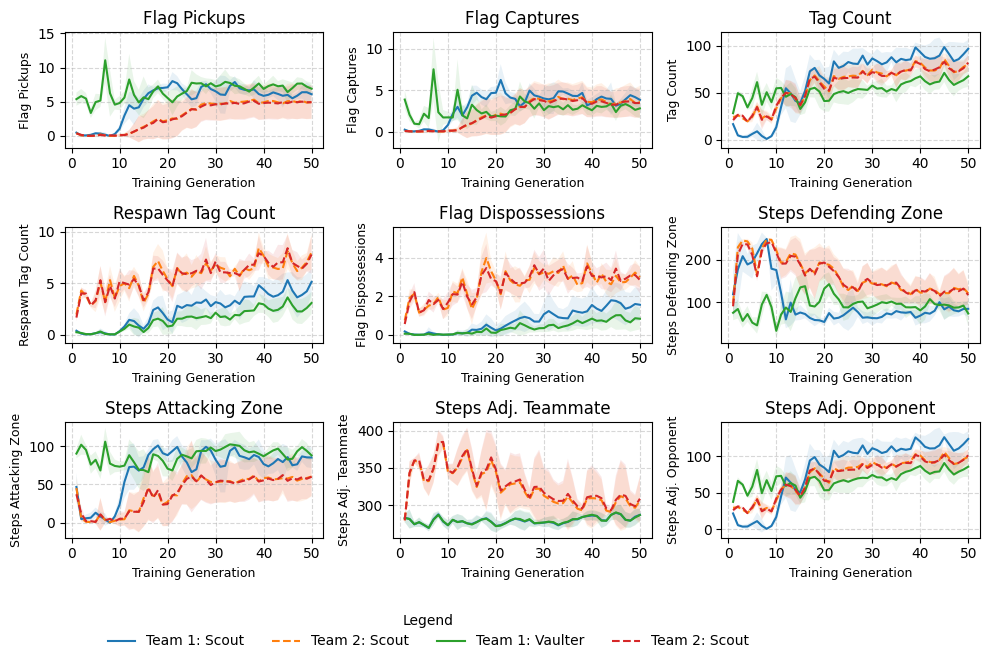
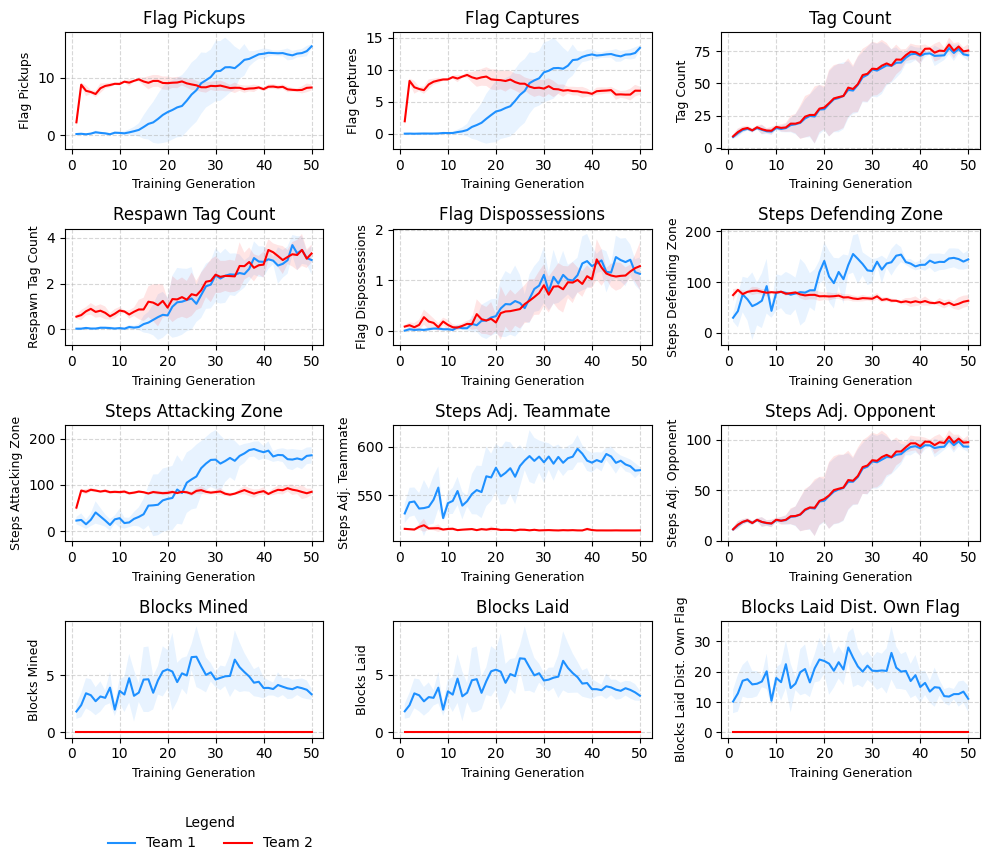
Description: This experiment tests whether the Guardian learns to leverage it's defensive abilities. Team 1 consists of a Scout and a Guardian (T1-S and T1-G), while Team 2 has two Scouts (T2-S and T2-S). A single diagonal row of block tiles separates the two teams, forcing a single area of movement in the top right quadrant of the game grid, forcing confrontation between teams.
Hypothesis: The Guardian will learn to defend its flag, whilst the T1 Scout will assume a more attacking role.
Results: Overall results indicate that T1-G learns to defend its flag whilst T1-S assumes a more attacking role, consistent with the hypothesis.
Generation 10: Both teams have learned the basics of the game and T1 show signs of specialisation; T1-G spends most of its time defending its flag, whilst T1-S spends more time attacking the opposing team.
Generation 30: T1 now consistently dominate matches.
Generation 50: In response to the emergent specialisation of T1, T2 have learnt a coordinated attack pattern, where one Scout takes a route at the top of the board while the other targets the center at the same time. In this way, T1-G must choose which opponent to pursue, giving the free opponent a better chance of survival and flag capture.
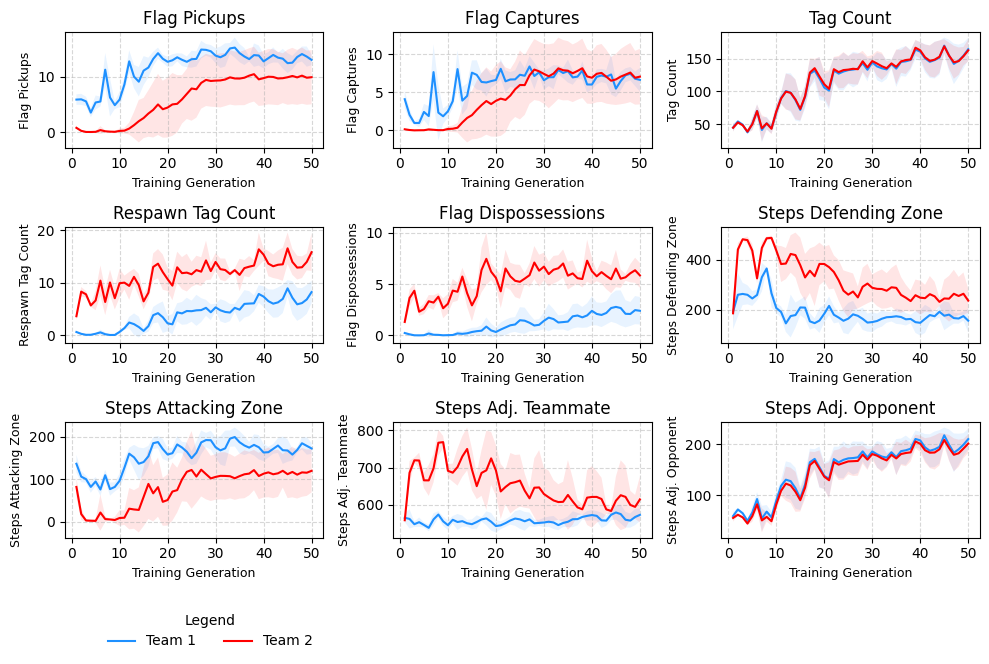
Description: This experiment tests whether the Vaulter learns to leverage its attacking attributes. Team 1 consists of a Scout and a Vaulter (T1-S and T1-V), while Team 2 has two Scouts (T2-S and T2-S). A horizontal wall blocks the direct path between the flags, forcing agents to take a longer route between flags - however, the Vaulter can pass through the wall.
Hypothesis: The T1 Vaulter will learn to use its vaulting ability to vault the block tiles to create a shorter route for flag capture and become a specialist in flag captures.
Results: T1-V learns to traverse the barrier in the middle of the grid in order to expedite flag captures. However, T1-V does not become adept at flag capturing as T2 learn to mitigate the superior mobility of T1-V over the course of training.
Generation 10: T1-V dominates flag pickups, captures and steps in the attacking zone in early training generations.
Generation 30: T1-V learns to jump over the fence in the middle of the grid by training generation 30.
Generation 50: By training generation 50, there is no material differences in flag metrics or positional metrics between T1-S and T1-V. T1-S engages opponents more, with more tags and more tags leading to respawns. T1-S is more inclined to engage opponents whilst T1-V is more evasive. This makes intuitive sense as the Vaulter incurs HP penalties from using its vaulting ability, and is more vulnerable to tags.
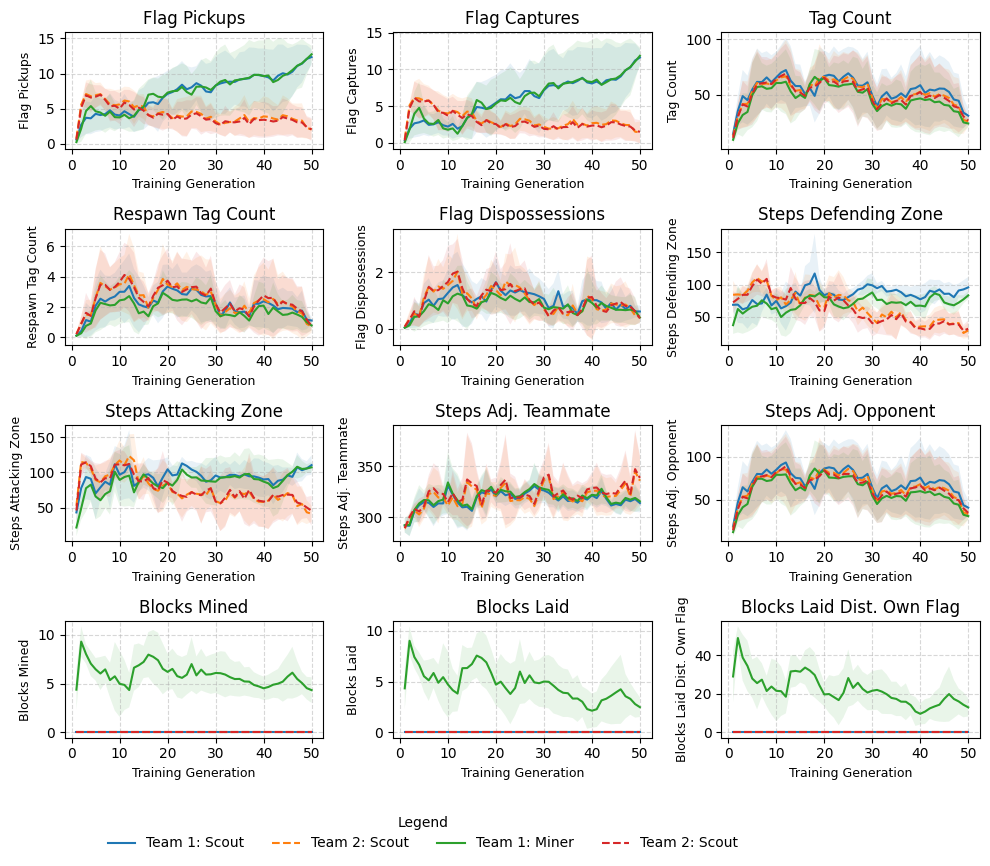
Description: This experiment tests whether a Miner agent can learn to manipulate the environment in order to free a trapped teammate and gain a numerical advantage. T1 consists of a Miner and a Scout (T1-S and T1-M), and T2 consists of two Scouts. One Scout from each team is trapped by destructible tiles, which can only be removed by a Miner agent.
Hypothesis: The T1 Miner will learn to remove the destructible tiles surrounding the T1 Scout, gaining a numerical advantage over the opposing team and creating more flag captures.
Results: T1-M learns to mine blocks to effectively free its T1-S teammate, creating a numerical advantage over T2. This results in total game dominance and is consistent with the hypothesis. Once freed, T1-S and T1-M share similar behaviours.
Generation 10: T2-S dominates flag pickups and captures in early generations of the game.
Generation 30: T1-M has learnt to reliably free its teammate and once freed, the T1-M and T1-S share similar routes of travel for flag capture.
Generation 50: T1 dominate matches and T1-M actively places tiles to obstruct T2-S.
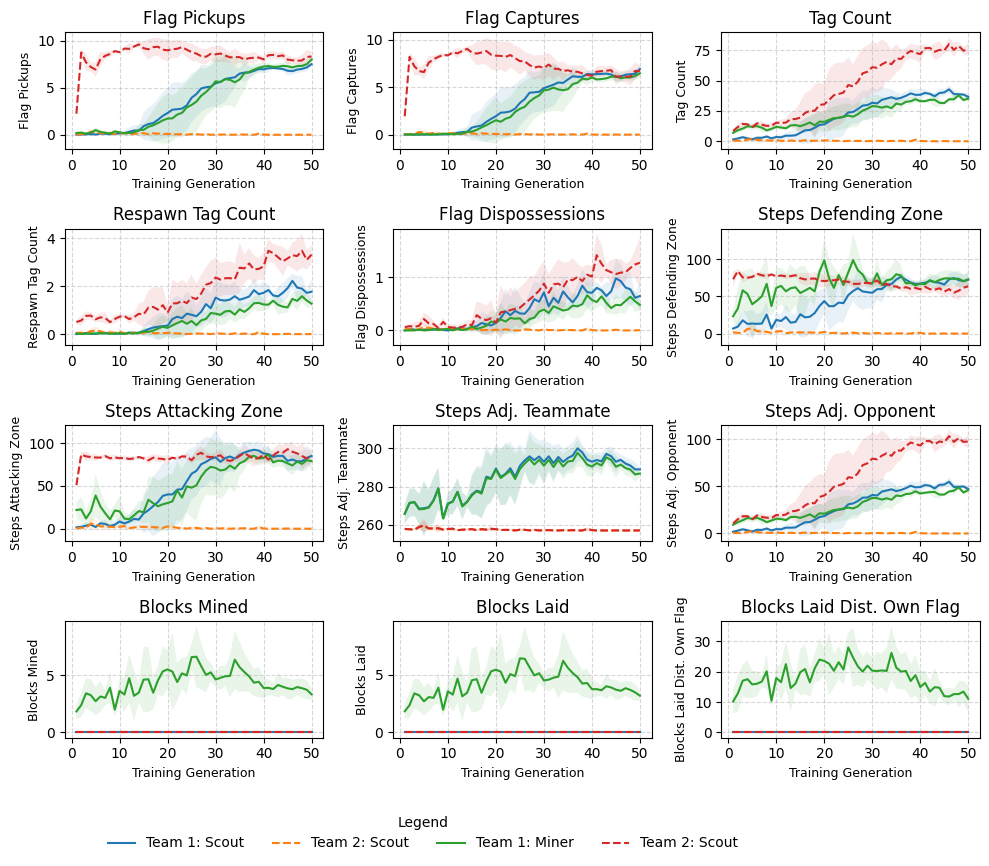
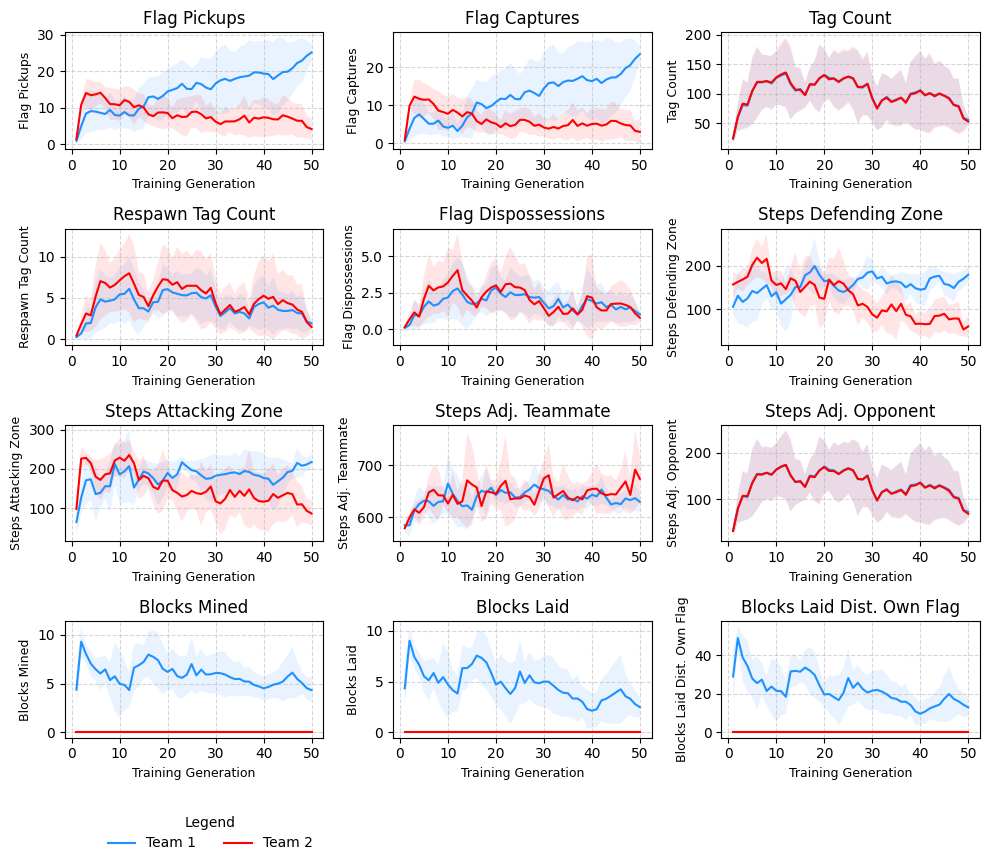
Description: This experiment examines whether the Miner agent can learn to mine and place blocks in order to trap the opposing team. T1 consists of a Miner and a Scout (T1-S and T1-M), and T2 consists of two Scouts. The spawning zones for each team have a narrow opening from which agents can enter and exit. Several destructible tiles are placed throughout the map, including a row of tiles between the two flags, forcing a longer route for capture.
Hypothesis: T1-M will learn to mine tiles and block the T2 spawning zone, preventing T2 from exiting their spawning zone when tagged and effectively nullifying their threat in the game.
Results: Overall results indicate that T1-M learns to mine and place blocks to trap T2 agents, consistent with my hypothesis. Adaptations made by T2 to mitigate the T1 are observed in later training generations.
Generation 10: T2 dominate flag pickups and captures in early generations of the game.
Generation 30: T1-M has learnt to mine a block and seal the entrance to the T2 spawning area. When T2 are tagged they are now trapped in their spawning zone. T1 dominate matches.
Generation 50: T1-M learns to remove a tile from the central barrier, expediting flag captures. T2 adapt once again and try to avoid being tagged by sticking to the peripheries of the main area. Although this mitigates being trapped early, ultimately it is not sufficient to win matches.
This study finds strong evidence that agents with different abilities naturally develop specialised roles when trained using reinforcement learning and self-play in a capture the flag setting.
Each agent type adopts behaviours suited to its strengths: Scouts balance attack and defence, Guardians focus on protecting their flag, Vaulters use speed to capture flags, and Miners reshape the environment to support teammates or hinder opponents. These roles remain consistent even as the environment becomes more complex.
Agents also adapt over time, responding to opponent strategies and sometimes changing or losing their specialisation. In some cases, strong imbalances between teams can limit the need for specialisation altogether.
Overall, the results show that reinforcement learning can produce coordinated, specialised behaviours without explicit instructions—simply by rewarding success in the game. This suggests broader potential for using RL to design effective teams of diverse agents in real-world applications, without needing to manually define roles or strategies.
Description: This experiment tests whether the Guardian learns to leverage it's defensive abilities. Team 1 consists of a Scout and a Guardian (T1-S and T1-G), while Team 2 has two Scouts (T2-S and T2-S). A single diagonal row of block tiles separates the two teams, forcing a single area of movement in the top right quadrant of the game grid, forcing confrontation between teams.
Hypothesis: The Guardian will learn to defend its flag, whilst the T1 Scout will assume a more attacking role.
Results: Overall results indicate that T1-G learns to defend its flag whilst T1-S assumes a more attacking role, consistent with the hypothesis.